Part A
Setup
For this part I will be leveraging the power of big data, and use the pretrained model DeepFloyd IF. By providing
the model a prompt and how many steps we want it to take, (more is higher quality), we can get AI generated images.
Throughout this whole project the seed I use is 137. Here are a few pictures at 50 and 500 inference steps.
The 500 ones look much crisper, and the prompts seem to be exactly what it is. Some are more cartoony than others.

50 steps of man in hat

500 steps of man in hat

50 steps of rocket

500 steps of rocket

50 steps of an oil painting of a snowy mountain village

500 steps of an oil painting of a snowy mountain village
1.1 Implementing the Forward Process
We want to take some clean image, and give it some noise so we can use the models denoise abilities to create a
new image. We can define a system of "time" where at t=0 the image is completely clean, and at t=T the image is pure
noise. The model works by denoising each timestep little by little rather than going from a completely noisy image
to a clean one.
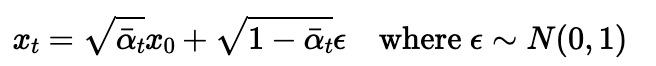
Forward equation
Here x_0 is a clean image and x_t is the image at noise level t, alpha is a coefficent that determines how noisy
we want our image and is already predetermined for us. I implemented this function to create noisy images from an
original image.

Campanile

Noisy Campanile at t=250

Noisy Campanile at t=500

Noisy Campanile at t=750
1.2 Classical Denoising
To contrast the power of diffusion models, here below is classical denoising (just a gaussian blur filter)

Classical Denoising at t=250
Noisy Campanile at t=250

Classical Denoising at t=500
Noisy Campanile at t=500

Classical Denoising at t=750

Noisy Campanile at t=750
1.3 One-Step Denoising
Now we can use our model to denoise since it has been trainied on such a large data set this should be much better
than classical methods. For all the parts below I used the prompt "a high quality image" except when otherwise
specified.

One-step Denoising at t=250
Noisy Campanile at t=250

One-step Denoising at t=500
Noisy Campanile at t=500

One-step Denoising at t=750
Noisy Campanile at t=750
1.4 Iterative Denoising
Instead of running the model 1000 times to denoise an image at noise level 1000, we can skip some steps by running
the formula below, where alpha is defined above but beta is just 1 - alpha. The prime notation indicated the time
step before the current one. We can stride our timesteps by taking steps of 30 instead of one, cutting down on a lot
of compute time.
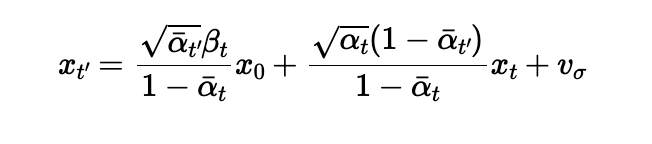
Denoise equation
Below is the results of iterative denoising, showing 5 different levels of noise and the final cleaned up image,
along side the guassian denoise, the original image and the one step denoised image.

t=90

t=240

t=390

t=540

t=690
Original

Iteratively denoised
One-Step denoised

Classical denoised
1.5 Diffusion Model Sampling
Instead of denoising to an existing image, if we denoise from pure noise we can get a brand new image. Here I used
the prompt, a high quality image.

Sample 1

Sample 2

Sample 3

Sample 4

Sample 5
1.6 Classifier-Free Guidance (CFG)
Those images are somewhat in the uncanny valley, so to fix this we can also add some unconditional noise. This
will decrease image diversification but massively increase quality. By averaging the noise with the equation e = e_u
+ g(e_c - e_u). Where e is the error, and g is gamma a factor we set.

Sample 1

Sample 2

Sample 3

Sample 4

Sample 5
1.7 Image-to-image Translation
Here we are going to take some image, then noise it a little bit and run the denoising algorithm, this will
provide us with a series of images that will progessively look more like the original.

Start=1

Start=3

Start=5

Start=7

Start=10

Start=20
Original

Start=1

Start=3

Start=5

Start=7

Start=10

Start=20

Original

Start=1

Start=3

Start=5

Start=7

Start=10

Start=20

Original
1.7.1 Editing Hand-Drawn and Web Images
Lets do the same thing but with some hand drawn images as well as some other fun ones.

Start=1

Start=3

Start=5

Start=7

Start=10

Start=20

Original

Start=1

Start=3

Start=5

Start=7

Start=10

Start=20

Original

Start=1

Start=3

Start=5

Start=7

Start=10

Start=20

Original
1.7.2 Inpainting
We can also selectively replace parts of an image by creating a mask and only noising and denoising that part of
the image.

Original

Mask

To replace

Final

Original

Mask

To replace

Final

Original

Mask

To replace

Final
1.7.3 Text-Conditional Image-to-image Translation
Here I denoise on a particular prompt to make a kind of blend between the prompt and the original.

Noise level 1

Noise level 3

Noise level 5

Noise level 7

Noise level 10

Noise level 20
Original

Noise level 1

Noise level 3

Noise level 5

Noise level 7
Noise level 10

Noise level 20
Original

Noise level 1

Noise level 3

Noise level 5

Noise level 7

Noise level 10

Noise level 20
Original
1.8 Visual Anagrams
We can keep playing around with these ideas by using two prompts, with two noises, we can flip one image and its
noise, average them together and add it to our image. This will create a "visual anagram" where looking at the image
right side up or upside down will show different things.

Old man

Campfire

Dog

Snowy village

Barista

Amalfi coast
1.9 Hybrid Images
Using the same idea as before but applying a low and highpass filter to each prompt and adding together the noise
will result in some hybrid images.

Man and Coast

Dog and snowy village

Skull and waterfall
Diffusion Models from Scratch
Above is only possible due to the vast ammounts of data these models are trained on. Here we will build one of
these models from scratch and train it on the MNIST dataset.
B.1.1 Implementing the UNet
Here I have implemented the blocks seen below, and with the help of pytorch put together a model to create digits.
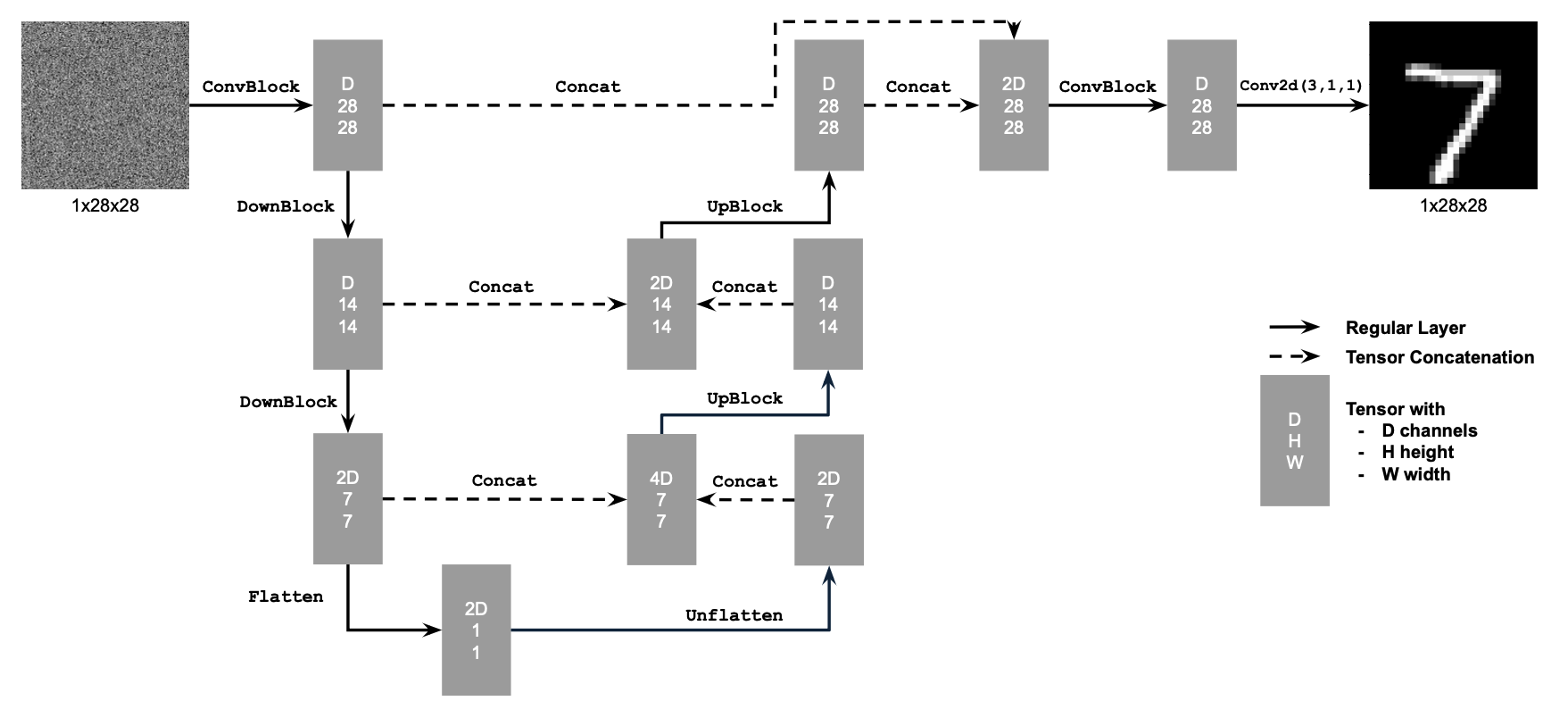
Model
B.1.2 Using the UNet to Train a Denoiser
Lets add some noise to our digits, below ive added normal noise to a digit at varing sigma levels

Noise at various sigmas
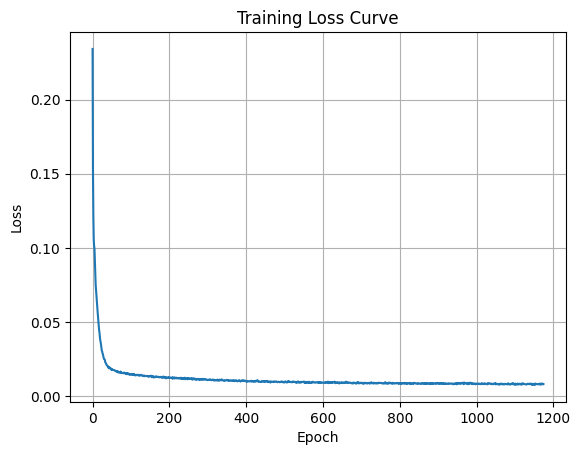
Ive trained the model to deblur images at sigma level 0.5, below is the loss curve, Ive optimized over an L2 loss.
Here are some results denoising using this model at different epochs.

Epoch 1
Epoch 5
Testing this on sigmas not trained on, it shows it lacks effectiveness for more noisy images.
B.2 Adding Time Conditioning to UNet
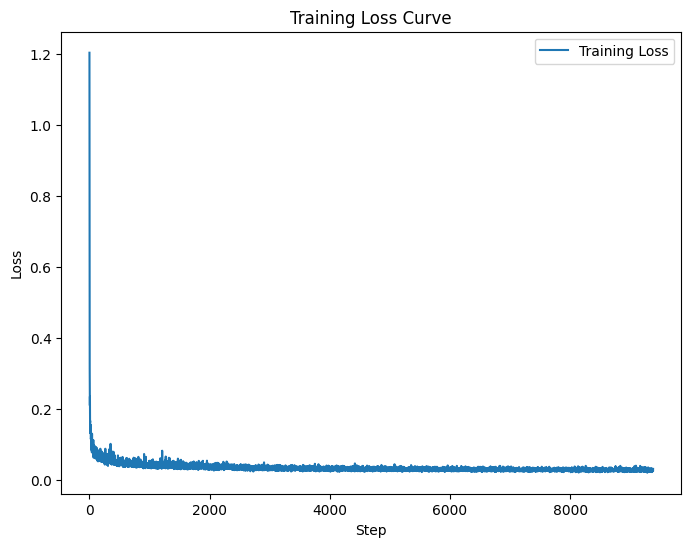
In order to make this better with more noise, we can add a fully connected layer into our model, below I've shown
the training losses, as well as a sampling at epoch 5 and 20
B.2 Adding Class-Conditioning to UNet
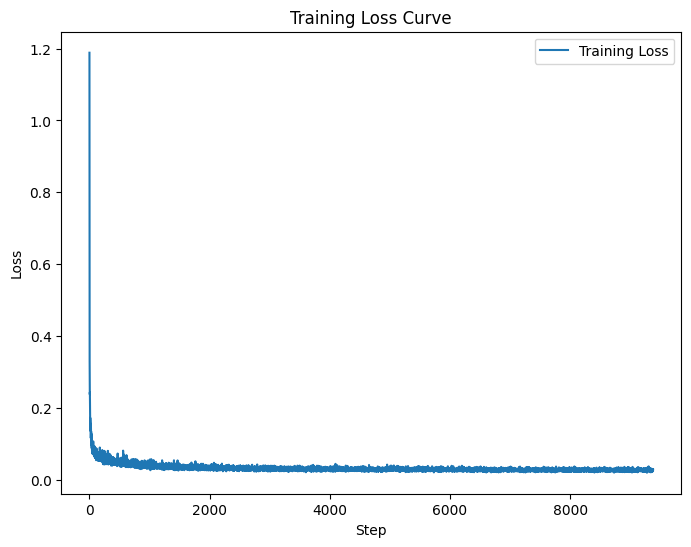
Again to make this better we can tell the model what class the number is training on, this should lead to better
results. Below is the trainign losses as well as samples from epoch 5 and 20.